正如其名,MapReduce的工作模式主要分为Map阶段和Reduce阶段。一个MapReduce任务(Job)通常将输入的数据集分割成独立的块,这些块被map任务以完全并行的方式处理。框架对映射(map)的输出进行排序,然后将其输入到...
”mapreduce 单词统计“ 的搜索结果
最后为了帮助大家深刻理解。
单词统计的MapReduce源码,统计多个文本数据集,最终输出每个单词的出现次数,可帮功能扩展修改 Map阶段 采集数据 Combiner阶段 合并数据 Reduce阶段 最终处理,进行排序等自定义操作 每个阶段都会打印对应的数据...
word1.txt(里面存放的是英语文章)idea2023.3.4旗舰版。

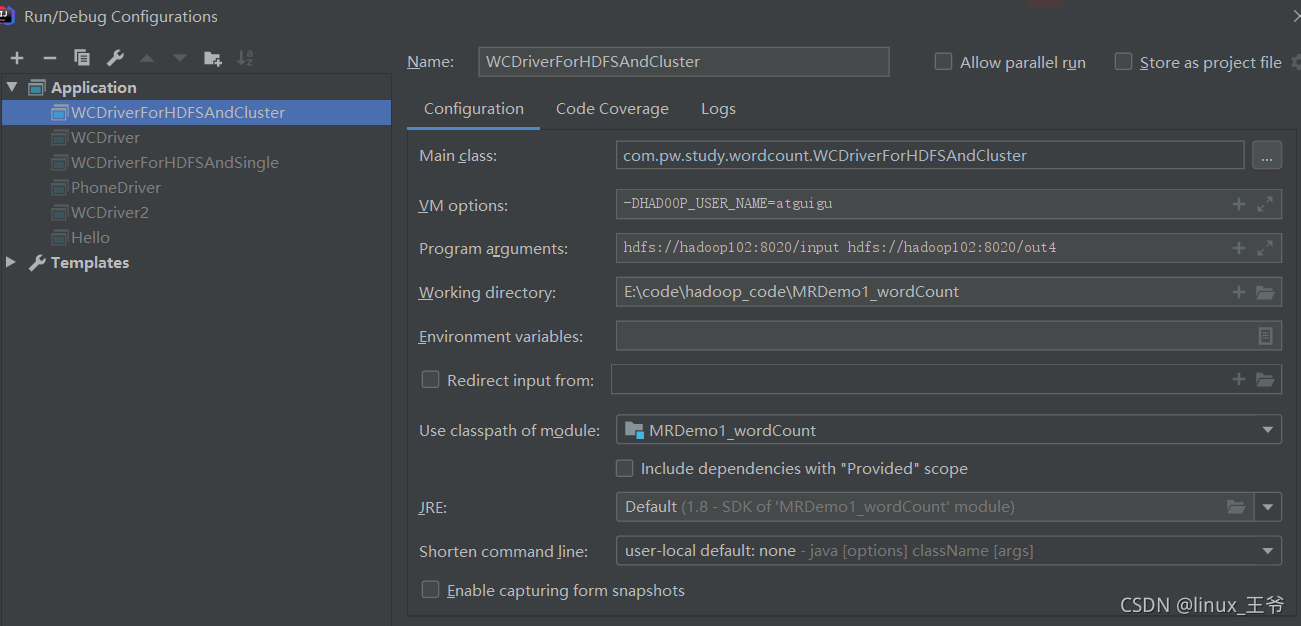
1、Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster 2、expected org.apache.hadoop.io.Text,recieved org.apache.hadoop.io.LongWritable
mapreduce 单词统计 案例 一、Hadoop MapReduce 构思体现在如下的三个方面: 1.如何对付大数据处理:分而治之 2.构建抽象模型:Map 和 Reduce Map: 对一组数据元素进行某种重复式的处理; Reduce: 对 Map 的...
提取数据 ...提取码:4vc4 package mr; // map 阶段 并行读取数据处理数据, 一个map默认读取 128M 的数据 13200 10 // map 阶段 并行读取数据处理数据, 一个map默认读取 128M 的数据 13200 20 // map 阶段...
MapReduce编程实践(Hadoop3.1.3)_厦大数据库实验室博客
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念”Map(映射)”和”Reduce(归约)”,是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了...
mapreduce单词统计的流程包括以下几个步骤: 1. 准备数据:从本地文件系统或者分布式文件系统(HDFS)中获取需要统计的文本数据。 2. 编程规范:按照MapReduce编程模型的规范,编写Mapper和Reducer的核心处理逻辑。 ...
掌握MapReduce单词统计原理。


文章目录一、准备数据二、MR的编程规范 一、准备数据 注意:准备的数据的格式必须是文本 编码必须是utf-8无bom! 二、MR的编程规范 MR的编程只需要将自定义的组件和系统默认组件进行组合,组合之后运行即可!...
使用Java编写mapreduce程序,核心思想是 分治 简单来说,mapreduce编程需要经过以下8个步骤 map阶段 第一步: 读取文件,解析成key value 对 k1 v1 第二步: 指定map逻辑,接收 k1 v1 转换成新的 k2 v2 ...
要求:给定一个文件,统计文本中单词出现的次数 用户编写的程序分为三个部分:Mapper、Reduce和Driver· 1、Mapper阶段 package cn.kgc.map; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop....

【代码】MapReduce 单词统计案列。
理解MapReduce在Hadoop体系结构中的角色,通过该实验后,能设计开发简单的MapReduce程序。 二、实验设备 计算机:CPU四核i7 6700处理器;内存8G; SATA硬盘2TB硬盘; Intel芯片主板;集成声卡、千兆网卡、显卡; 20...
统计单词个数 创建项目 按下图所示在resources目录下创建文件夹input,在其中提供文件wc.txt: 注意:不要创建output目录,系统会自动创建。否则会报目录已存在的错。wc.txt文件的内容: hello hadoop and hello ...
读取文本数据按空格进行拆分 import org.apache.hadoop.io....import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; //LongWritable 偏移量 long 表示改行在文件中的位置,而不是行号 //Text ma
No1、mapreduce,‘wordcount案例’编程思路No1-1 :MapReduce运行步骤input -->map -->reduce-->output No1-1-1 : inputinput阶段:将文件中每行的数据转换成一个{key,value}键值对 key:是数据在每行中的偏移量,...
MapReduce:单词统计,单项求和 前奏:pom.xml <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.11</v...
用python写mapreduce还需要了解HadoopStreaming HadoopStreaming是可运行特殊脚本的mapperredece作业的工具 使用格式如下: $HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/hadoop-streaming.jar \ -input ...


推荐文章
- 阿里云企业邮箱的stmp服务器地址_阿里云stmp地址-程序员宅基地
- c++ 判断数学表达式有效性_高考数学大题如何"保分"?学霸教你六大绝招!...-程序员宅基地
- 处理office365登录出现服务器问题_o365登陆显示网络异常-程序员宅基地
- Nginx RTMP源码分析--ngx_rtmp_live_module源码分析之添加stream_ngx_rtmp_live_module 原理-程序员宅基地
- 基于Ansible+Python开发运维巡检工具_automation_inspector.tar.gz-程序员宅基地
- Linux Shell - if 语句和判断表达式_shell if elif-程序员宅基地
- python升序和降序排序_Python排序列表数组方法–通过示例解释升序和降序-程序员宅基地
- jenkins 构建前执行shell_Jenkins – 在构建之前执行脚本,然后让用户确认构建-程序员宅基地
- 如何完全卸载MySQL_mysql怎么卸载干净-程序员宅基地
- AndroidO Treble架构下HIDL服务查询过程_found dead hwbinder service-程序员宅基地